|
I am a first-year Ph.D. student at Electrical and Computer Engineering Department, Princeton University, advised by Prof. Chi Jin. Previously, I did my undergraduate at Yuanpei College, Peking University. I am interested in the intersection of RL and LLMs, especially on certifiable reasoning. |

|
 |
Project / Paper / Model / Code / X |
 |
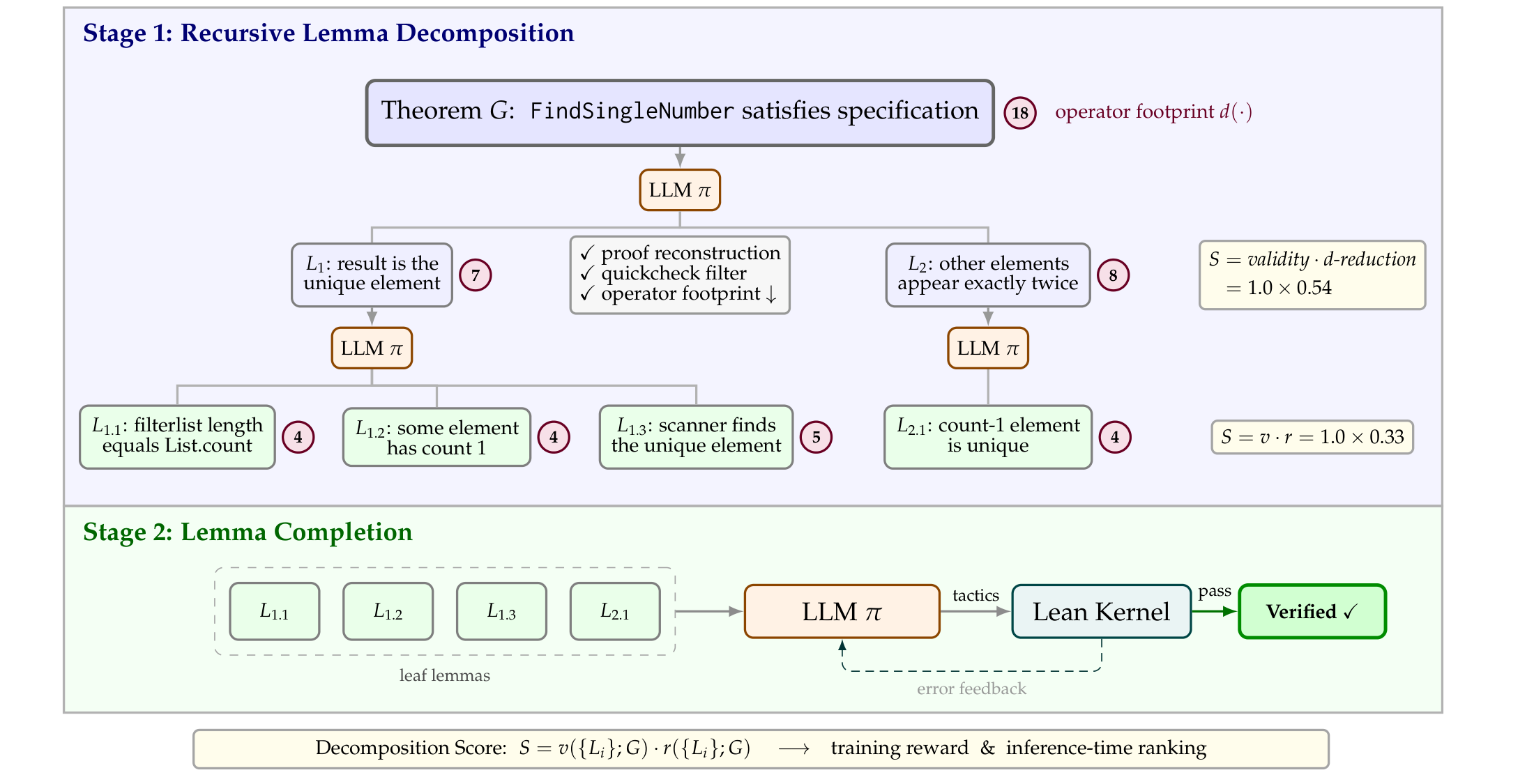
AI4MATH@ICML 2025 (Oral), ICLR 2026 |
 |
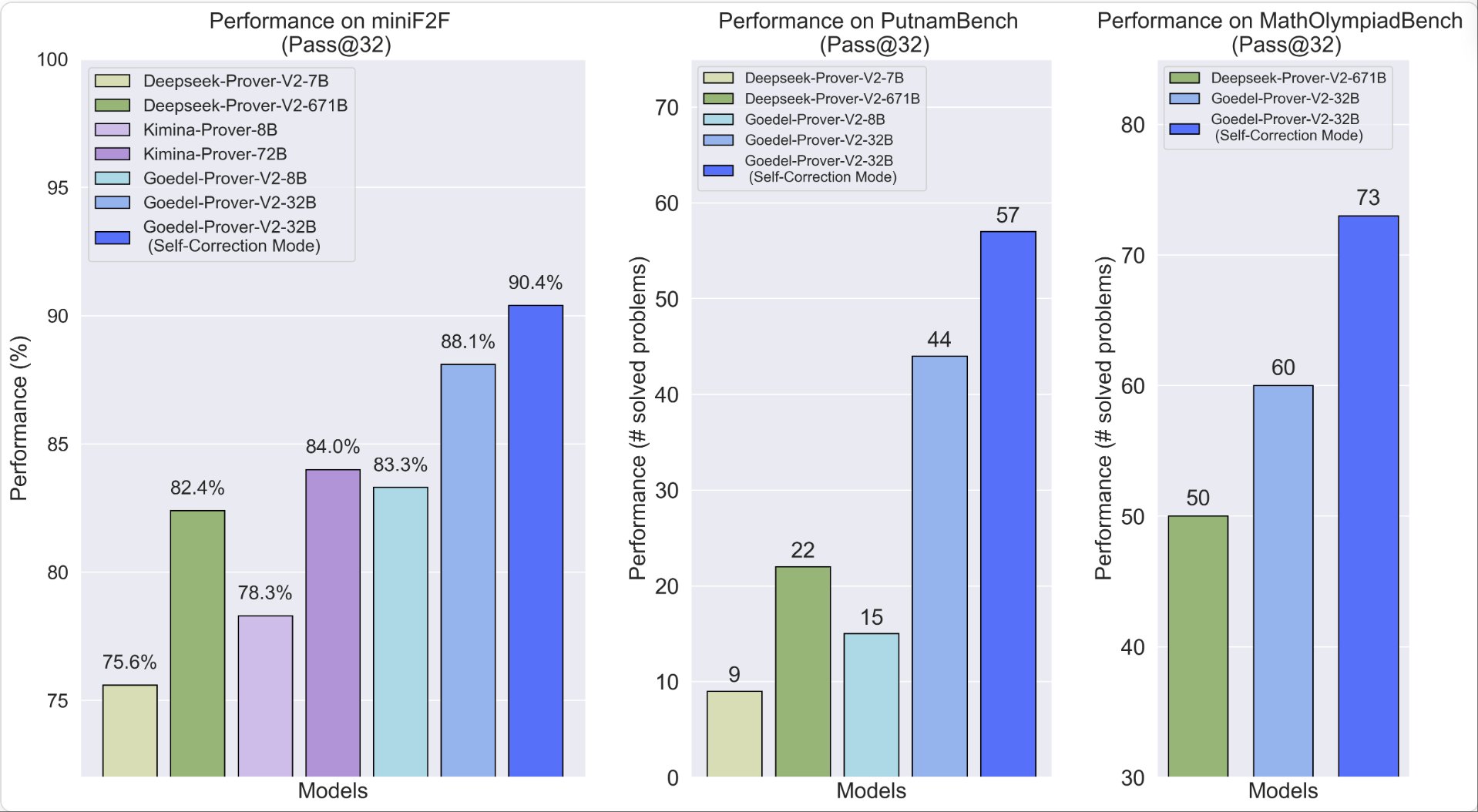
ICML 2026 (Spotlight); Arxiv |
|
|
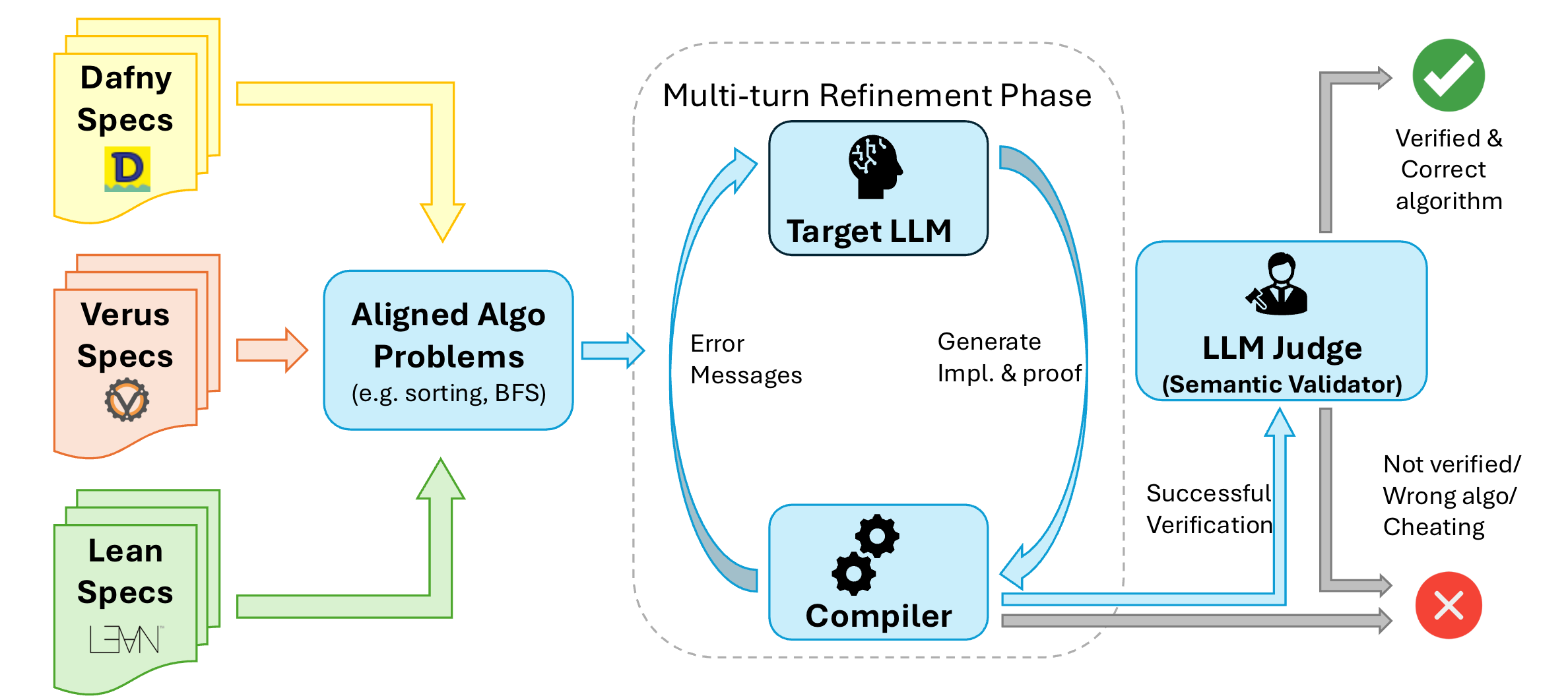
ICLR 2025 Workshop: Quantify Uncertainty and Hallucination in Foundation Models |
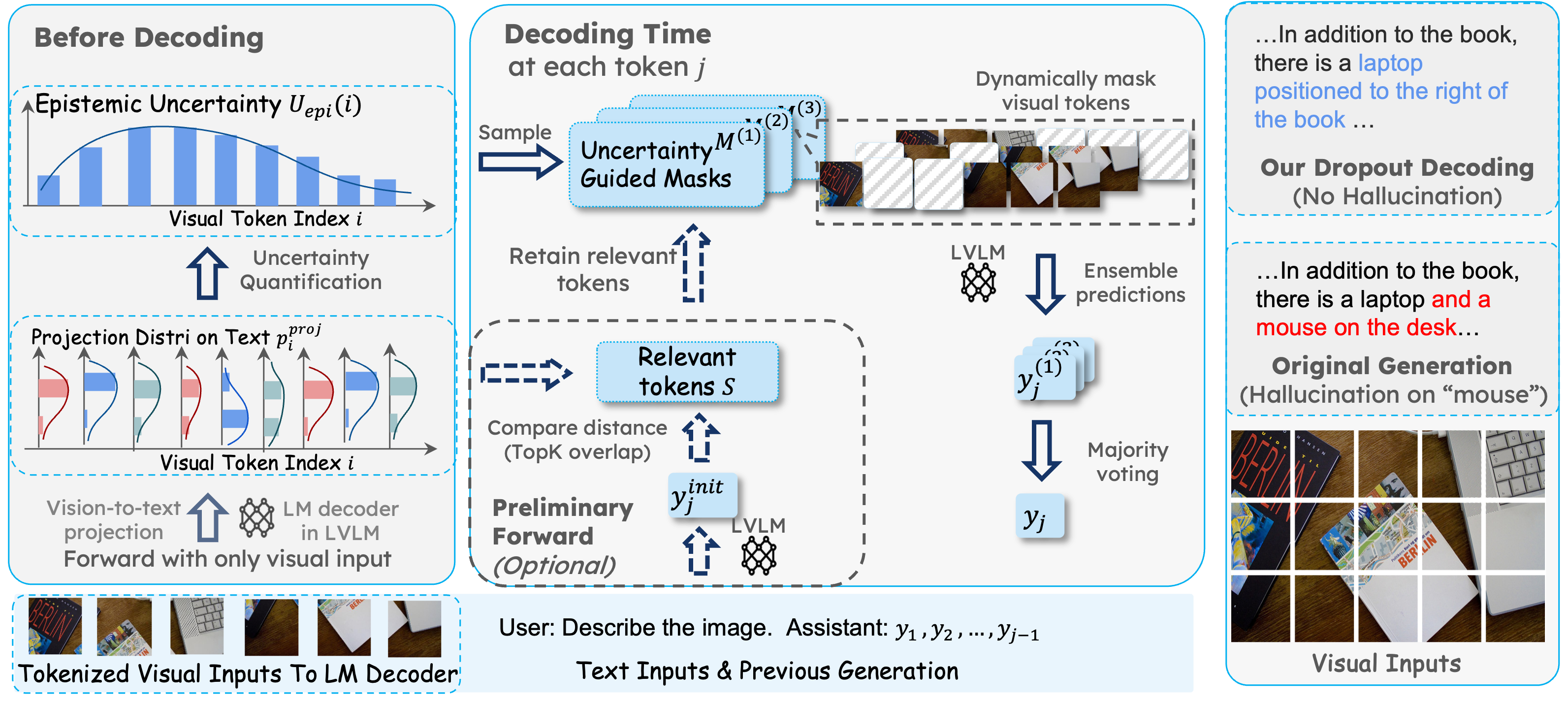 |
NeurIPS 2025 |
|
|
IEEE T-PAMI; Arxiv |
|
|
NeurIPS 2024 |
|
|
NeurIPS 2024 (DB Track) |
 |
ACL 2025; ICLR 2025 Workshop: Reasoning and Planning for LLMs (Oral) |
 |
ByteDance Seed
2025.05 - 2025.08 Research Intern Working on RL for Tool-using Agentic LLMs. |
|
UC San Diego
2024.04 - 2024.11 Research Intern Advisor: Prof. Zhiting Hu |
|
 |
PAIR Lab: PKU Alignment and Interaction Research Lab
2023.05 - Present Research Intern Advisor: Prof. Yaodong Yang |
|
|

|
This template is a modification to Jon Barron's website. |